Umelá inteligencia začína výrazne zasahovať do spoločenských vied: preniká do dotazníkov, urýchľuje písanie štúdií a zároveň otvára otázku, či bude výsledkom viac chýb, alebo kvalitnejší výskum. Podľa vedcov je problém najmä v tom, že odpovede generované veľkými jazykovými modelmi môžu skresliť dáta o ľudskom správaní, no tie isté nástroje sa dajú využiť aj na dôkladnejšie overovanie výsledkov.
Will AI ruin the social sciences — or revolutionize them?
Psychologička Raluca Rilla z Max Planck Institute for Human Development v Berlíne narazila pri zbere odpovedí do prieskumu na vetu: „I don’t experience confusion in the same way humans do.“ Práve takéto odpovede naznačujú, že časť respondentov môže pri vyplňovaní používať LLM. Rilla a jej kolegovia odhadujú, že až 45 % odpovedí v podobných prieskumoch môže byť skopírovaných a vložených z výstupov jazykových modelov. Niekedy môže ísť len o jazykové uhladenie textu. V iných prípadoch sa podľa nej môže stať, že celý proces od registrácie až po odoslanie odpovede vybaví stroj.
Pre spoločenské vedy je to citlivý problém. Veľká časť odboru stojí na dotazníkoch, prieskumoch verejnej mienky a analýze rozsiahlych súborov dát, ktoré často vznikli na iný pôvodný účel. Práve v takýchto dátach sa dajú zdanlivé súvislosti ľahko vyťažiť zo šumu. Ak do toho vstúpi AI, ktorá pomáha generovať odpovede aj celé texty štúdií, rastie riziko, že do odbornej literatúry preniknú presvedčivo vyzerajúce, no metodicky slabé závery.
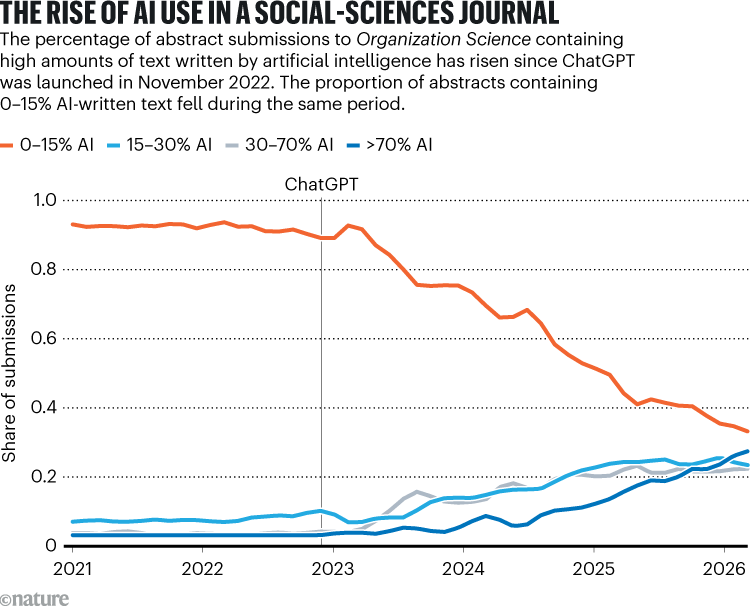
Na tento trend upozorňujú výskumníci z psychológie, politológie, ekonómie aj oblasti prieskumov verejnej mienky. David Lazer z Northeastern University varuje, že AI-asistované analýzy môžu zaplaviť časopisy pochybnými zisteniami, pretože výrazne zrýchľujú výrobu štúdií. Časopis Organization Science napríklad oznámil, že od novembra 2022, keď bol ChatGPT prvýkrát verejne sprístupnený, vzrástol počet zaslaných rukopisov o 42 %. Editori pri ich analýze pomocou nástroja na detekciu textu od Pangram Labs usúdili, že tento nárast vo veľkej miere poháňa práve AI. Do februára obsahovala takmer tretina zaslaných článkov abstrakt, ktorý bol prevažne alebo úplne vytvorený AI, a ďalších 40 % malo abstrakt čiastočne písaný s pomocou AI.
Podobný tlak hlásia aj ďalšie časti akademického prostredia. Kevin Munger z European University Institute predpovedal, že popredné politologické časopisy môžu tento rok zaznamenať nárast počtu zaslaných prác o 50 %. PsyArXiv, preprintový server pre psychológiu, podľa meta-vedca Jamieho Cumminsa dostával toľko rukopisov, že musel zaradiť skoršie ľudské kontroly do procesu predbežného posudzovania.
Lazer v rozhovore pre Nature ukázal, ako ľahko sa dá s pomocou LLM pripraviť presvedčivo pôsobiaci akademický text. Na základe dát z projektu Civic Health and Institutions Project’s 50 States Survey, ktorý v USA sleduje dôveru verejnosti a legitimitu inštitúcií, nechal model v priebehu hodiny vytvoriť 28-stranový článok. Text obsahoval prehľad literatúry, tabuľky priamo z dátového súboru aj presvedčivé grafy a obrázky. Základné pozorovanie sa týkalo užívania GLP-1 agonistov, ktoré boli pôvodne vyvinuté na liečbu cukrovky a dnes sú známe aj tým, že pomáhajú pri chudnutí. Rýchly pohľad na dáta naznačil, že najčastejšími užívateľmi nemusia byť nevyhnutne ľudia s klinickou potrebou, ako je diabetes alebo obezita. Lazer však zdôrazňuje, že podstatné nie je samotné konkrétne zistenie, ale to, ako jednoducho možno takýto text vyrobiť.
To je jadro obavy: AI neprodukuje iba rýchlosť, ale aj objem. Ak výskumník dokáže za krátky čas pripraviť viacero analyticky tenkých, no navonok presvedčivých článkov, vedecké časopisy a recenzenti môžu čeliť náporu, ktorý bude ťažké rozlíšiť od poctivého výskumu. Björn Hommel z Leipzig University sa obáva, že neustála hrozba „znečistenia“ LLM môže oslabiť dôveru v behaviorálne a spoločenské vedy.
Nie všetci však vidia len riziko. Joshua Tucker z New York University upozorňuje, že rovnaké nástroje môžu výskum aj posilniť. AI vie rýchlo spracovať zložité dátové súbory, porovnávať viacero štatistických postupov a preverovať, ako citlivý je výsledok na zmenu analytickej metódy. Takéto použitie by mohlo pomôcť odhaliť metodické chyby a tlačiť odbor k robustnejším štandardom. Prakticky to znamená, že AI môže byť nielen zdrojom šumu, ale aj nástrojom na dôslednejšiu kontrolu toho, či zistenie obstojí pri prísnejšom testovaní.
Najbezprostrednejší problém sa dnes týka online prieskumov, najmä tých, ktoré prebiehajú cez platformy ako Amazon Mechanical Turk a Prolific. Keď ľudia dostávajú malú odmenu za odpoveď, vzniká motivácia systém obísť. Rilla preto do svojich prieskumov zaviedla sériu kontrolných pascí, takzvaných honeypots, ktoré majú odhaliť použitie LLM a umožniť vyradiť podozrivé odpovede. Patria medzi ne napríklad riadky takmer neviditeľného textu v zdrojovom kóde otázok, ktoré sa môžu preniesť do skopírovaných odpovedí, alebo skryté inštrukcie pre AI, aby odpovedala iba reťazcom písmen X. Sama Rilla to opisuje ako preteky v zbrojení: čím budú modely schopnejšie zakryť svoju stopu, tým sofistikovanejšie budú musieť byť aj obranné metódy výskumníkov.
Pri najdôležitejších štúdiách založených na ľudských odpovediach by sa podľa niektorých vedcov možno mohlo vrátiť aj fyzicky kontrolované vyplňovanie dotazníkov pod dohľadom. Takýto krok by však mal vlastné nevýhody. Práve obmedzená rozmanitosť a skreslenie takýchto vzoriek patrili medzi dôvody, prečo sa v minulosti rozšírili webové prieskumy všeobecnej populácie.
Ďalšou spornou oblasťou sú takzvané „silicon samples“, teda virtuálne populácie respondentov vytvorené modelom. Tento pojem zaviedla práca z roku 2022, v ktorej americkí výskumníci ukázali, že LLM trénovaný na reálnych socio-demografických charakteristikách populácie dokáže generovať syntetických respondentov. V praxi to znamená, že výskumník môže model požiadať, aby odpovedal tak, akoby išlo napríklad o prieskum medzi tisíckou Švajčiarov s určitými vlastnosťami.
Takýto prístup by teoreticky mohol lacno a rýchlo modelovať ťažko dostupné skupiny a umožniť klásť im otázky aspoň v simulovanej forme. Niektoré prieskumné firmy už syntetických účastníkov ponúkajú komerčne a využívajú ich v marketingovom výskume. Časť vedcov sa však obáva, že by sa podobné postupy mohli rozšíriť aj do spoločenských vied bez dostatočnej opatrnosti. Cummins vo svojom výskume ukázal, že podľa nastavenia modelu, napríklad parametra „temperature“, možno získať veľmi rozdielne výsledky. Elson je ešte kritickejší a tvrdí, že pri takomto nastavení sa dá v podstate nadiktovať, či výsledok hypotézu podporí, alebo vyvráti.
Výsledný obraz preto nie je jednoduchý. Umelá inteligencia môže spoločenské vedy podkopať, ak bude vyrábať nepresné odpovede, slabé články a ľahko manipulovateľné syntetické dáta. Zároveň však môže zvýšiť metodickú prísnosť, ak ju vedci použijú na kontrolu analýz, overovanie odolnosti výsledkov a hľadanie chýb. O budúcnosti odboru tak pravdepodobne nerozhodne samotná technológia, ale to, aké pravidlá, kontroly a profesijné normy sa okolo nej podarí vybudovať.
Prečo sú spoločenské vedy zraniteľnejšie
Spoločenské vedy pracujú s témami, ktoré sa často opierajú o sebahodnotenie ľudí, postoje, preferencie a deklarované správanie. Práve preto sú dotazníky a rozsiahle prieskumy pre mnohé odbory kľúčovým zdrojom dát. Ak do takého systému vstupujú odpovede vytvorené strojom, problém nie je len technický. Mení sa samotný vzťah medzi výskumníkom a človekom, ktorého chce skúmať.
Vo všeobecnosti platí, že pri dátach z prieskumov je náročné odlíšiť skutočný spoločenský jav od náhodného vzorca alebo skreslenia. Keď navyše AI vie produkovať jazyk, ktorý pôsobí prirodzene a konzistentne, môže sa zhoršiť schopnosť odhaliť, ktoré odpovede vznikli autenticky a ktoré nie. To je jedna z príčin, prečo odborníci varujú práve pri behaviorálnom a sociálnom výskume hlasnejšie než v niektorých iných disciplínach.
V zdrojovom texte sa objavujú dva odlišné, ale prepojené problémy. Prvým je kontaminácia vstupných dát, teda situácia, keď respondent použije chatbot na formulovanie alebo úplné vytvorenie odpovede. Druhým je kontaminácia výstupu vedeckej práce, keď AI pomáha príliš rýchlo vyrábať články, ktoré síce vyzerajú odborne, ale môžu stáť na krehkých základoch.
Tieto dve roviny sa môžu navzájom posilňovať. Ak sú pôvodné dáta neisté a zároveň je jednoduché z nich okamžite vygenerovať uhladený rukopis, odborný systém môže byť zahltený textami, ktoré prejdú prvým dojmom, no neponúkajú spoľahlivé poznanie. Samotný jazykový štýl článku pritom nemusí prezradiť, či je jeho obsah pevný, alebo len elegantne zabalený.
Kde môže AI výskumu skutočne pomôcť
Zdroj zároveň pripomína, že rovnaké nástroje sa dajú použiť aj opačne. V širšom zmysle môže AI zrýchliť overovanie analytických postupov, porovnávanie alternatívnych modelov a kontrolu toho, či výsledok pretrvá aj po zmene metodiky. To je dôležité najmä tam, kde sa vedci snažia zistiť, či konkrétny efekt nie je len dôsledkom jedného špecifického nastavenia analýzy.
Ak sa z AI stane pomocník pri testovaní robustnosti a pri hľadaní metodických slabín, môže prispieť k vyššej spoľahlivosti publikovaných zistení. Samotný zdroj nehovorí, že sa to už vo veľkom deje, ale ukazuje, prečo časť vedcov nechce technológiu len odmietnuť. V hre je aj možnosť, že časopisy časom začnú vyžadovať prísnejšie analytické štandardy práve preto, že ich AI robí uskutočniteľnejšími.
Syntetickí respondenti a hranica medzi modelom a realitou
Myšlienka virtuálnych populácií je lákavá najmä tam, kde je ťažké alebo drahé osloviť reálnych ľudí. Všeobecne možno povedať, že modelované vzorky môžu byť užitočné ako technický experiment alebo doplnkový nástroj na testovanie postupov. Problém nastáva vtedy, keď sa začnú zamieňať za skutočné ľudské odpovede.
Práve tu sa otvára metodická aj etická hranica. Ak výsledok závisí od toho, ako výskumník nastaví model, potom nevypovedá len o populácii, ale aj o rozhodnutiach pri konfigurácii systému. Zdroj preto upozorňuje, že bez veľmi jasných pravidiel by sa syntetické vzorky mohli stať cestou k záverom, ktoré budú pôsobiť presne, no nebudú mať pevný vzťah k realite.
Čo bude nasledovať a čo zostáva neisté
Zatiaľ nie je jasné, aké účinné budú obranné mechanizmy proti AI v online prieskumoch a či budú držať krok s rýchlym vývojom modelov. Nie je ani isté, do akej miery sa akademické časopisy, preprintové servery a grantové systémy prispôsobia vyššiemu objemu textov pripravovaných s pomocou AI.
Jasné však je, že spoločenské vedy vstupujú do obdobia, v ktorom už nebude stačiť posudzovať len to, čo výskumník tvrdí, ale aj ako získal dáta, ako písal analýzu a kde presne technológia do procesu vstúpila. Budúca dôveryhodnosť odboru tak zrejme bude závisieť od transparentnosti, lepších kontrol a od ochoty odlišovať medzi užitočnou asistenciou a zásahom, ktorý deformuje samotný predmet výskumu.
Na poskytovanie tých najlepších skúseností používame technológie, ako sú súbory cookie na ukladanie a/alebo prístup k informáciám o zariadení. Súhlas s týmito technológiami nám umožní spracovávať údaje, ako je správanie pri prehliadaní alebo jedinečné ID na tejto stránke. Nesúhlas alebo odvolanie súhlasu môže nepriaznivo ovplyvniť určité vlastnosti a funkcie.
Funkčné
Vždy aktívny
Technické uloženie alebo prístup sú nevyhnutne potrebné na legitímny účel umožnenia použitia konkrétnej služby, ktorú si účastník alebo používateľ výslovne vyžiadal, alebo na jediný účel vykonania prenosu komunikácie cez elektronickú komunikačnú sieť.
Predvoľby
Technické uloženie alebo prístup je potrebný na legitímny účel ukladania preferencií, ktoré si účastník alebo používateľ nepožaduje.
Štatistiky
Technické úložisko alebo prístup, ktorý sa používa výlučne na štatistické účely.Technické úložisko alebo prístup, ktorý sa používa výlučne na anonymné štatistické účely. Bez predvolania, dobrovoľného plnenia zo strany vášho poskytovateľa internetových služieb alebo dodatočných záznamov od tretej strany, informácie uložené alebo získané len na tento účel sa zvyčajne nedajú použiť na vašu identifikáciu.
Marketing
Technické úložisko alebo prístup sú potrebné na vytvorenie používateľských profilov na odosielanie reklamy alebo sledovanie používateľa na webovej stránke alebo na viacerých webových stránkach na podobné marketingové účely.